Kafka là gì? Nguyên lý hoạt động của Kafka
🧠 Kafka là gì?
Apache Kafka là một nền tảng streaming dữ liệu phân tán theo thời gian thực. Nó cho phép gửi, lưu trữ, xử lý và truyền tải dữ liệu giữa các hệ thống phần mềm một cách đáng tin cậy và mở rộng tốt.
Kafka được thiết kế để xử lý:
-
Dữ liệu lớn (big data)
-
Dữ liệu liên tục, tốc độ cao (streaming)
-
Hệ thống sự kiện (event-driven architecture)
🎯 Kafka dùng để làm gì?
Kafka hoạt động như một message broker mạnh mẽ, thường dùng trong:
| Ứng dụng | Ví dụ thực tế |
|---|---|
| Thu thập log mạng / hệ thống | NetFlow, IDS/IPS, firewall |
| Phân tích real-time | Phát hiện tấn công, dự báo lưu lượng |
| Giao tiếp microservice | Hệ thống thanh toán, TMĐT |
| Pipeline AI/ML | Kafka → Python AI Model → Dashboard |
| Đồng bộ dữ liệu | Kafka Connect → DB, S3, ClickHouse |
🔁 Nguyên lý hoạt động của Kafka
Kafka hoạt động theo mô hình Publish-Subscribe (Pub/Sub):
-
Producer gửi dữ liệu (message) vào một topic.
-
Kafka lưu message vào partition của topic.
-
Consumer đăng ký nhận dữ liệu từ topic.
-
Consumer có thể xử lý, lưu trữ, phân tích hoặc trực quan hóa dữ liệu.
📌 Kafka đảm bảo thứ tự và độ bền dữ liệu bằng offset, log bất biến và replication.
🧱 Mô hình kiến trúc tổng quát Kafka
+-----------------+
Producers -->| Kafka |--> Consumers
| Broker |
+--------+--------+
|
Partitions
↓
Stored on disk
🎯 Các thành phần chính:
| Thành phần | Vai trò |
|---|---|
| Producer | Gửi dữ liệu đến Kafka (log, sự kiện...) |
| Topic | Kênh dữ liệu (giống như tên bảng trong DB) |
| Partition | Phân vùng giúp mở rộng, lưu dữ liệu song song |
| Broker | Máy chủ Kafka lưu trữ dữ liệu (nhiều broker tạo thành cluster) |
| Consumer | Ứng dụng đọc dữ liệu từ topic |
| Consumer Group | Cho phép load-balancing khi nhiều consumer |
| Zookeeper (phiên bản cũ) | Quản lý metadata, đồng bộ cluster |
| Kafka Controller (KRaft mới) | Thay thế Zookeeper, nhẹ và đơn giản hơn |
📦 Dữ liệu Kafka lưu trữ thế nào?
-
Kafka lưu dữ liệu dưới dạng log bất biến (append-only) trong file.
-
Dữ liệu được chia theo partition, mỗi message có một offset duy nhất.
-
Kafka có cơ chế retention: giữ dữ liệu theo thời gian hoặc dung lượng.
🔄 Quy trình xử lý dữ liệu (data pipeline)
Thiết bị mạng / App
↓
[Logstash / Fluentd] → Kafka (Topic: log-netflow)
↓
Consumer xử lý (Python, Flink, Spark)
↓
ClickHouse / Elasticsearch / Dashboard
🧠 Đặc điểm kỹ thuật nổi bật
| Tính năng | Mô tả |
|---|---|
| Thông lượng cao | Hàng triệu message/giây |
| Thứ tự đảm bảo | Trong từng partition |
| Chịu lỗi tốt | Replication đa broker |
| Mở rộng dễ dàng | Thêm broker, partition |
| Kết nối linh hoạt | Kafka Connect tới nhiều hệ thống khác |
📌 Kafka trong hạ tầng log mạng thực tế
-
Thiết bị mạng (router, DNS, firewall...) gửi log → Kafka
-
Kafka lưu log → các topic phân loại theo nguồn log
-
Consumer nhận log:
-
Phân tích bằng AI (Isolation Forest, LSTM)
-
Hiển thị qua Grafana
-
Gửi cảnh báo nếu bất thường
-
📘 Ví dụ thực tế: topic phân chia
| Topic | Dữ liệu chứa |
|---|---|
vnix-netflow |
NetFlow từ router |
vnix-dns |
Truy vấn DNS |
vnix-alerts |
Log từ IDS / AI phát hiện |
vnix-raw-log |
Tổng hợp log chưa xử lý |
🛠️ Tóm tắt ưu điểm của Kafka
| Ưu điểm | Mô tả |
|---|---|
| Hiệu năng cao | Streaming tốc độ cao, delay thấp |
| Lưu trữ bền vững | Lưu log 7 ngày, 30 ngày... tùy retention |
| Dễ tích hợp với các hệ thống | ClickHouse, Spark, Flink, Python |
| Tốt cho dữ liệu thời gian thực | Monitoring, dashboard, phân tích AI |
Dưới đây là chi tiết triển khai lab Kafka trên máy ảo Ubuntu (local VM hoặc cloud như AWS EC2), gồm hướng dẫn cài đặt, phân chia công việc từng tuần và công cụ đi kèm.
🧭 1. Chuẩn bị môi trường Ubuntu
✅ Yêu cầu phần cứng tối thiểu cho máy ảo:
-
CPU: 2 vCPU
-
RAM: 4 GB (tốt nhất 8 GB)
-
Disk: 20+ GB
-
OS: Ubuntu 20.04+ (khuyên dùng 22.04)
🛠️ Cài đặt phần mềm cơ bản:
sudo apt update && sudo apt upgrade -y
sudo apt install openjdk-11-jdk wget net-tools unzip curl -y
📦 2. Cài đặt Kafka (standalone, không dùng Docker)
📁 Tạo thư mục:
mkdir -p ~/kafka-lab && cd ~/kafka-lab
🌐 Tải Kafka (ví dụ: Kafka 3.7.0):
wget https://downloads.apache.org/kafka/3.7.0/kafka_2.13-3.7.0.tgz
tar -xvzf kafka_2.13-3.7.0.tgz
cd kafka_2.13-3.7.0
🚀 Khởi động Zookeeper và Kafka:
# Terminal 1 - Zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
# Terminal 2 - Kafka broker
bin/kafka-server-start.sh config/server.properties
📅 3. Lộ trình học & thực hành trên máy ảo Ubuntu (10 tuần)
| Tuần | Nội dung học | Thực hành |
|---|---|---|
| 1 | Kafka cơ bản | Cài đặt Kafka, tạo topic, gửi/nhận message |
| 2 | Topic, partition | Tạo topic nhiều partition, quan sát offset |
| 3 | Producer/Consumer config | Thử acks=0/1/all, test mất message |
| 4 | Cluster | Cấu hình Kafka broker thứ 2 (port 9093), test replication |
| 5 | Kafka Client (Java/Python) | Viết producer, consumer đơn giản |
| 6 | Kafka Connect | Kết nối PostgreSQL ↔ Kafka |
| 7 | Kafka Streams | Lọc dữ liệu theo thời gian |
| 8 | Retention, cleanup | Cấu hình retention.ms, test xóa log |
| 9 | Monitoring | Cài Prometheus + Grafana, export metrics |
| 10 | Bảo mật & benchmark | Bật SSL, ACL, test hiệu năng với perf-test |
📂 4. Cấu trúc thư mục lab gợi ý
~/kafka-lab/
├── kafka_2.13-3.7.0/
├── logs/
├── config/
│ ├── server-1.properties
│ ├── server-2.properties
├── scripts/
│ ├── create_topic.sh
│ ├── producer.py
│ ├── consumer.py
├── connectors/
│ └── jdbc-postgres/
🔌 5. Mẹo và công cụ gợi ý
-
SSH và tmux: để giữ phiên Kafka chạy khi mất kết nối
-
Kafka Manager (hoặc AKHQ): dễ quan sát topic/partition
-
rsyslog hoặc filebeat: quan sát log server Kafka
-
Firewall: mở port
2181,9092,9093, nếu cần truy cập từ ngoài
Dưới đây là tổng quan kiến trúc Kafka bao gồm mô hình vật lý, mô hình logic, nguyên lý hoạt động, cùng với mô tả quy trình cài đặt – tạo topic – gửi/nhận message.
🧱 1. Kiến trúc tổng quan Kafka
🧭 1.1 Mô hình vật lý (Physical Architecture)
Kafka được triển khai dưới dạng hệ thống phân tán gồm nhiều node gọi là broker. Một số thành phần vật lý chính:
-
Kafka Broker: máy chủ chạy Kafka (thường là nhiều máy)
-
Zookeeper (hoặc KRaft Controller từ Kafka 2.8+): quản lý metadata cluster (trong mode cũ)
-
Kafka Producer: ứng dụng gửi dữ liệu vào Kafka
-
Kafka Consumer: ứng dụng nhận dữ liệu từ Kafka
-
Kafka Topic: nơi lưu trữ message, phân chia theo partition
-
Kafka Cluster: tập hợp nhiều broker (ví dụ: broker1, broker2, broker3)
📌 Ví dụ:
+-------------------+ +-------------------+ +-------------------+
| Producer App 1 | ---> | Kafka Broker 1| <--> | Broker 2 |
| Producer App 2 | ---> | (Leader of P1)| <--> | (Replica) |
+-------------------+ +-------------------+ +-------------------+
Consumer Group A <--- reads from Topic X (Partitioned)
🧠 1.2 Mô hình logic (Logical Architecture)
| Thành phần | Vai trò |
|---|---|
| Topic | Dòng dữ liệu được định danh (VD: sensor_data, logs) |
| Partition | Mỗi topic chia thành nhiều partition – đơn vị lưu trữ & xử lý song song |
| Offset | ID duy nhất đánh dấu vị trí của message trong 1 partition |
| Producer | Gửi dữ liệu vào topic/partition |
| Consumer | Nhận dữ liệu từ topic/partition |
| Consumer Group | Nhóm consumer hoạt động cùng nhau để xử lý dữ liệu song song |
🔄 2. Nguyên lý hoạt động Kafka (dòng dữ liệu)
-
Producer gửi message vào 1 topic → Kafka ghi vào partition tương ứng.
-
Mỗi message có một offset duy nhất trong partition.
-
Kafka ghi message vào log file, không thay đổi, chỉ ghi nối thêm.
-
Consumer đọc message từ offset hiện tại (hoặc từ đầu) theo nhu cầu.
-
Consumer có thể commit offset để lưu vị trí đã xử lý.
-
Kafka không xóa message ngay sau khi tiêu thụ mà tuân theo
retention.ms.
Kafka = commit log phân tán, append-only, durability cao, tốc độ cao
⚙️ 3. Triển khai Lab: Cài đặt – Tạo topic – Gửi/Nhận message
✅ Bước 1: Cài Kafka (trên Ubuntu)
wget https://downloads.apache.org/kafka/3.7.0/kafka_2.13-3.7.0.tgz
tar -xvzf kafka_2.13-3.7.0.tgz
cd kafka_2.13-3.7.0
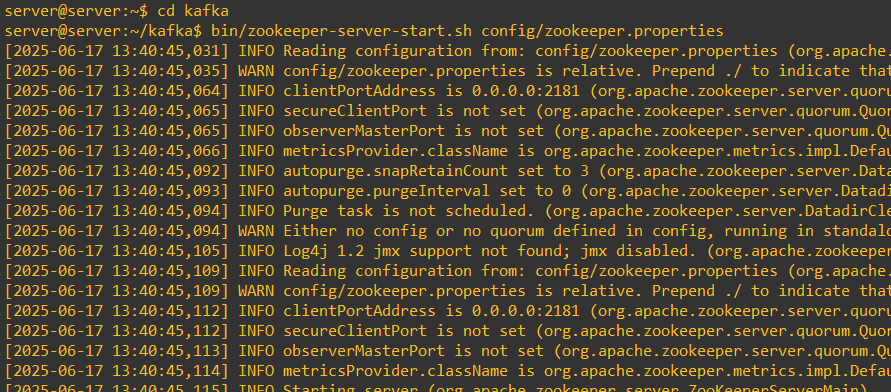
✅ Bước 2: Khởi động Zookeeper + Kafka
# Terminal 1
bin/zookeeper-server-start.sh config/zookeeper.properties
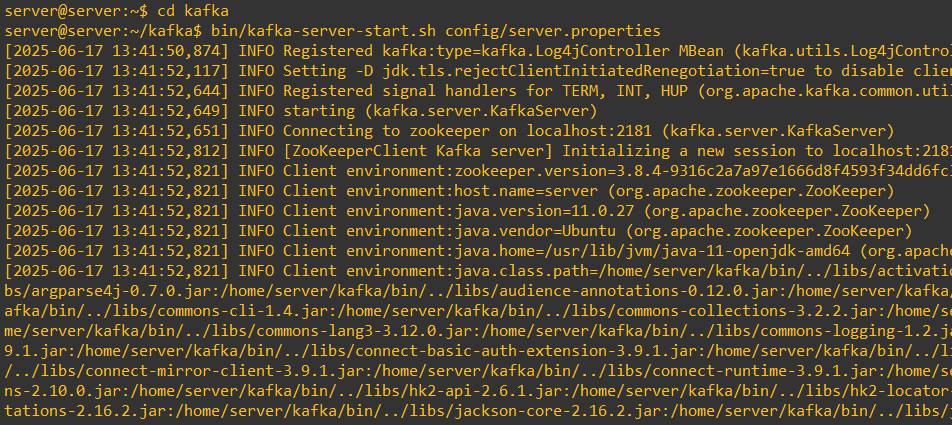
# Terminal 2
bin/kafka-server-start.sh config/server.properties
✅ Bước 3: Tạo topic
bin/kafka-topics.sh --create \
--topic my-topic \
--bootstrap-server localhost:9092 \
--partitions 3 --replication-factor 1
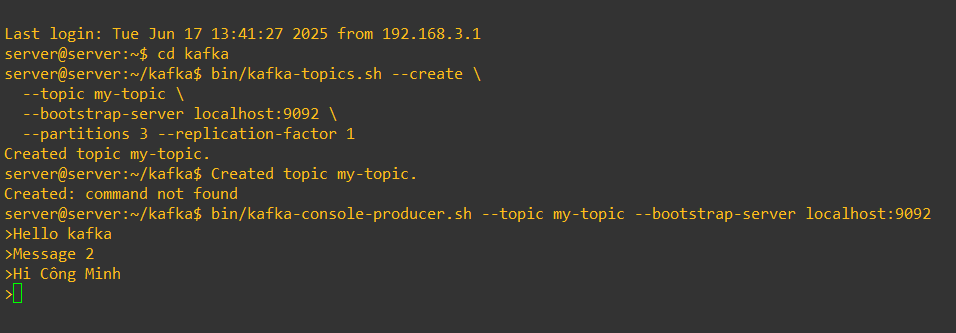
✅ Bước 4: Gửi message (Producer)
bin/kafka-console-producer.sh --topic my-topic --bootstrap-server localhost:9092
> Hello Kafka
> Message 2
✅ Bước 5: Nhận message (Consumer)
bin/kafka-console-consumer.sh --topic my-topic --from-beginning \
--bootstrap-server localhost:9092
🔍 Ví dụ dòng dữ liệu Kafka (visual logic)
Producer --> Kafka Broker (my-topic, Partition 0)
|
V
[Hello Kafka] [Message 2] [Message 3] → Offset 0, 1, 2
Consumer ---> Reads from offset 0 onward