Numpy là gì? ứng dụng numpy vào bài toán thực tế
TỔNG HỢP LÝ THUYẾT NUMPY TOÀN DIỆN
1. GIỚI THIỆU VỀ NUMPY
NumPy là gì?
- Tên đầy đủ: Numerical Python
- Định nghĩa: Thư viện Python cho tính toán khoa học
- Đối tượng chính: N-dimensional array (ndarray)
- Ngôn ngữ: Viết bằng C và Python (nhanh hơn Python thuần túy)
Tại sao dùng NumPy?
- ⚡ Tốc độ: Nhanh hơn list Python 10-100 lần
- 🧮 Toán học: Hỗ trợ đầy đủ phép toán vectorized
- 💾 Bộ nhớ: Tiết kiệm bộ nhớ hơn list Python
- 🔗 Tích hợp: Nền tảng cho Pandas, Matplotlib, Scikit-learn
- 📊 Broadcasting: Phép toán giữa các mảng khác kích thước
2. CẤU TRÚC DỮ LIỆU NDARRAY
Khái niệm cơ bản
import numpy as np
# Tạo array
arr = np.array([1, 2, 3, 4, 5])
Thuộc tính quan trọng
| Thuộc tính | Ý nghĩa | Ví dụ |
|---|---|---|
shape |
Kích thước mảng | (3, 4) |
size |
Tổng số phần tử | 12 |
ndim |
Số chiều | 2 |
dtype |
Kiểu dữ liệu | int64, float64 |
itemsize |
Kích thước mỗi phần tử (bytes) | 8 |
Các kiểu dữ liệu (dtype)
- Số nguyên:
int8,int16,int32,int64 - Số thực:
float16,float32,float64 - Số phức:
complex64,complex128 - Boolean:
bool - Chuỗi:
U10(Unicode 10 ký tự)
3. TẠO MẢNG (ARRAY CREATION)
Từ dữ liệu có sẵn
# Từ list
np.array([1, 2, 3])
np.array([[1, 2], [3, 4]])
# Từ tuple
np.array((1, 2, 3))
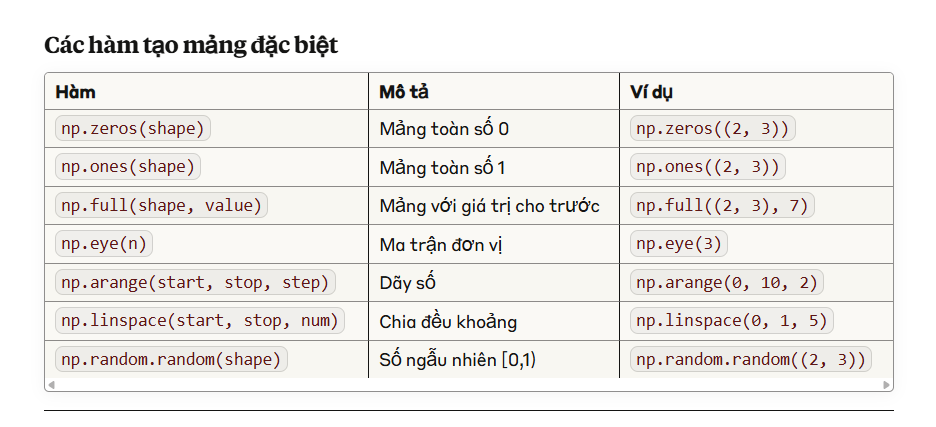
Các hàm tạo mảng đặc biệt
| Hàm | Mô tả | Ví dụ |
|---|---|---|
np.zeros(shape) |
Mảng toàn số 0 | np.zeros((2, 3)) |
np.ones(shape) |
Mảng toàn số 1 | np.ones((2, 3)) |
np.full(shape, value) |
Mảng với giá trị cho trước | np.full((2, 3), 7) |
np.eye(n) |
Ma trận đơn vị | np.eye(3) |
np.arange(start, stop, step) |
Dãy số | np.arange(0, 10, 2) |
np.linspace(start, stop, num) |
Chia đều khoảng | np.linspace(0, 1, 5) |
np.random.random(shape) |
Số ngẫu nhiên [0,1) | np.random.random((2, 3)) |
4. INDEXING VÀ SLICING
Indexing cơ bản
arr = np.array([10, 20, 30, 40, 50])
arr[0] # 10 (phần tử đầu)
arr[-1] # 50 (phần tử cuối)
arr[1:4] # [20, 30, 40]
arr[::2] # [10, 30, 50] (bước nhảy 2)
Indexing 2D
arr_2d = np.array([[1, 2, 3], [4, 5, 6]])
arr_2d[0, 1] # 2
arr_2d[1, :] # [4, 5, 6] (hàng thứ 2)
arr_2d[:, 1] # [2, 5] (cột thứ 2)
Boolean Indexing
arr = np.array([1, 2, 3, 4, 5])
mask = arr > 3
arr[mask] # [4, 5]
arr[arr > 3] # [4, 5] (cách ngắn gọn)
Fancy Indexing
arr = np.array([10, 20, 30, 40, 50])
indices = [0, 2, 4]
arr[indices] # [10, 30, 50]
5. PHÉP TOÁN VỚI MẢNG
Phép toán Element-wise
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
a + b # [5, 7, 9]
a - b # [-3, -3, -3]
a * b # [4, 10, 18]
a / b # [0.25, 0.4, 0.5]
a ** 2 # [1, 4, 9]
Phép toán với scalar
arr = np.array([1, 2, 3])
arr + 5 # [6, 7, 8]
arr * 2 # [2, 4, 6]
Phép toán logic
a = np.array([True, False, True])
b = np.array([False, True, True])
a & b # [False, False, True] (AND)
a | b # [True, True, True] (OR)
~a # [False, True, False] (NOT)
6. BROADCASTING
Khái niệm
Broadcasting cho phép thực hiện phép toán giữa các mảng có shape khác nhau.
Quy tắc Broadcasting
- So sánh shape từ dimension cuối cùng về đầu
- Dimensions tương thích nếu:
- Bằng nhau
- Một trong hai bằng 1
- Một trong hai không tồn tại
Ví dụ Broadcasting
# (3, 4) + (4,) = (3, 4)
a = np.ones((3, 4))
b = np.array([1, 2, 3, 4])
result = a + b
# (3, 1) + (4,) = (3, 4)
a = np.array([[1], [2], [3]])
b = np.array([10, 20, 30, 40])
result = a + b
7. CÁC HÀM THỐNG KÊ
Thống kê cơ bản
| Hàm | Mô tả | Ví dụ |
|---|---|---|
np.sum() |
Tổng | np.sum(arr) |
np.mean() |
Trung bình | np.mean(arr) |
np.median() |
Trung vị | np.median(arr) |
np.std() |
Độ lệch chuẩn | np.std(arr) |
np.var() |
Phương sai | np.var(arr) |
np.min() |
Giá trị nhỏ nhất | np.min(arr) |
np.max() |
Giá trị lớn nhất | np.max(arr) |
Thống kê theo trục (axis)
arr = np.array([[1, 2, 3],
[4, 5, 6]])
np.sum(arr, axis=0) # [5, 7, 9] (tổng theo cột)
np.sum(arr, axis=1) # [6, 15] (tổng theo hàng)
np.mean(arr, axis=0) # [2.5, 3.5, 4.5]
8. RESHAPE VÀ MANIPULATE
Thay đổi shape
arr = np.arange(12) # [0, 1, 2, ..., 11]
arr.reshape(3, 4) # Ma trận 3x4
arr.reshape(-1, 4) # Tự động tính số hàng
arr.flatten() # Chuyển về 1D
arr.ravel() # Chuyển về 1D (view)
Transpose
arr = np.array([[1, 2, 3],
[4, 5, 6]])
arr.T # Chuyển vị
np.transpose(arr) # Tương tự arr.T
Ghép mảng
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
np.concatenate([a, b]) # [1, 2, 3, 4, 5, 6]
np.hstack([a, b]) # Ghép ngang
np.vstack([a, b]) # Ghép dọc
Tách mảng
arr = np.arange(9).reshape(3, 3)
np.split(arr, 3, axis=0) # Tách thành 3 phần theo hàng
np.hsplit(arr, 3) # Tách ngang
np.vsplit(arr, 3) # Tách dọc
9. SẮP XẾP VÀ TÌM KIẾM
Sắp xếp
arr = np.array([3, 1, 4, 1, 5])
np.sort(arr) # [1, 1, 3, 4, 5]
np.argsort(arr) # [1, 3, 0, 2, 4] (chỉ số)
arr.sort() # Sắp xếp in-place
Tìm kiếm
arr = np.array([1, 3, 5, 7, 9])
np.searchsorted(arr, 4) # 2 (vị trí chèn)
np.where(arr > 5) # (array([3, 4]),) (chỉ số)
np.argmax(arr) # 4 (chỉ số max)
np.argmin(arr) # 0 (chỉ số min)
10. PHÉP TOÁN TUYẾN TÍNH
Phép toán ma trận
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
np.dot(A, B) # Tích ma trận
A @ B # Tương tự np.dot
np.linalg.inv(A) # Ma trận nghịch đảo
np.linalg.det(A) # Định thức
np.linalg.eig(A) # Eigenvalues và eigenvectors
Giải hệ phương trình
# Ax = b
A = np.array([[2, 1], [1, 3]])
b = np.array([1, 2])
x = np.linalg.solve(A, b) # Nghiệm của hệ
11. CÁC HÀM TOÁN HỌC
Hàm lượng giác
x = np.pi/4
np.sin(x), np.cos(x), np.tan(x)
np.arcsin(x), np.arccos(x), np.arctan(x)
Hàm mũ và logarit
np.exp(x) # e^x
np.log(x) # ln(x)
np.log10(x) # log10(x)
np.power(x, y) # x^y
np.sqrt(x) # căn bậc 2
Làm tròn
arr = np.array([1.234, 5.678])
np.round(arr, 2) # [1.23, 5.68]
np.floor(arr) # [1., 5.]
np.ceil(arr) # [2., 6.]
12. RANDOM TRONG NUMPY
Tạo số ngẫu nhiên
np.random.seed(42) # Đặt seed
np.random.random(5) # 5 số từ [0, 1)
np.random.randint(1, 10, 5) # 5 số nguyên từ [1, 10)
np.random.normal(0, 1, 5) # Phân phối chuẩn
np.random.choice([1,2,3,4]) # Chọn ngẫu nhiên
Xáo trộn
arr = np.arange(10)
np.random.shuffle(arr) # Xáo trộn in-place
np.random.permutation(arr) # Tạo hoán vị mới
13. FILE I/O
Lưu và đọc file
arr = np.array([1, 2, 3, 4, 5])
# Binary format (.npy)
np.save('data.npy', arr)
loaded = np.load('data.npy')
# Text format
np.savetxt('data.txt', arr)
loaded = np.loadtxt('data.txt')
# CSV
np.savetxt('data.csv', arr, delimiter=',')
loaded = np.loadtxt('data.csv', delimiter=',')
14. PERFORMANCE VÀ BEST PRACTICES
Tối ưu hóa hiệu suất
- Dùng vectorized operations thay vì vòng lặp
- Tránh copy không cần thiết (dùng view khi có thể)
- Chọn dtype phù hợp (int32 vs int64)
- Dùng in-place operations khi có thể
- Pre-allocate arrays thay vì append
So sánh hiệu suất
# ❌ Chậm - vòng lặp Python
result = []
for i in range(len(arr)):
result.append(arr[i] * 2)
# ✅ Nhanh - vectorized
result = arr * 2
15. CÁC PACKAGE MỞ RỘNG
Ecosystem NumPy
- Pandas: Xử lý dữ liệu dạng bảng
- Matplotlib: Vẽ đồ thị
- SciPy: Tính toán khoa học nâng cao
- Scikit-learn: Machine Learning
- OpenCV: Xử lý ảnh
- TensorFlow/PyTorch: Deep Learning
16. DEBUG VÀ TROUBLESHOOTING
Lỗi thường gặp
- Shape mismatch: Kiểm tra kích thước mảng
- Data type issues: Chuyển đổi dtype
- Memory errors: Giảm kích thước hoặc tăng RAM
- Broadcasting errors: Hiểu rõ quy tắc broadcasting
Debug tools
arr.shape # Kiểm tra kích thước
arr.dtype # Kiểm tra kiểu dữ liệu
np.info(arr) # Thông tin chi tiết
arr.flags # Flags của array
KẾT LUẬN
NumPy là nền tảng cốt lõi của scientific computing trong Python. Việc thành thạo NumPy sẽ giúp bạn:
- ⚡ Viết code nhanh và hiệu quả
- 🧮 Xử lý dữ liệu số lượng lớn
- 🔬 Thực hiện tính toán khoa học phức tạp
- 🚀 Chuẩn bị cho các thư viện nâng cao khác
Lời khuyên: Thực hành nhiều với các ví dụ thực tế để nắm vững các khái niệm!
HƯỚNG DẪN TÍNH TOÁN THỦ CÔNG TỪNG BƯỚC
Dữ liệu gốc:
Hàng 0: 120, 180, 150, 160, 130, 200, 140, 175, 110, 90
Hàng 1: 130, 170, 160, 155, 135, 190, 145, 180, 115, 100
Hàng 2: 125, 165, 155, 158, 132, 185, 148, 178, 118, 95
Hàng 3: 135, 175, 160, 162, 140, 195, 150, 182, 120, 105
Hàng 4: 140, 180, 165, 168, 145, 200, 155, 185, 125, 110
Hàng 5: 138, 178, 162, 166, 143, 198, 152, 184, 122, 108
Hàng 6: 128, 170, 158, 160, 139, 190, 149, 179, 119, 102
Hàng 7: 132, 172, 161, 163, 142, 192, 151, 181, 121, 104
Hàng 8: 134, 174, 163, 165, 144, 194, 153, 183, 123, 106
Hàng 9: 136, 176, 164, 167, 146, 196, 154, 186, 124, 107
Hàng 10: 138, 178, 166, 169, 148, 198, 156, 188, 126, 109
Hàng 11: 140, 180, 168, 170, 150, 200, 158, 190, 128, 111
1. THÔNG TIN CƠ BẢN
Cách đếm:
- Số hàng: Đếm từ 0 đến 11 = 12 hàng
- Số cột: Đếm các số trong 1 hàng = 10 cột
- Tổng phần tử: 12 × 10 = 120 phần tử
2. TÌM GIÁ TRỊ NHỎ NHẤT (MIN)
Cách làm: Duyệt qua từng số và so sánh
Quá trình:
- Bắt đầu: min = 120 (số đầu tiên)
- So sánh: 120 vs 180 → min = 120
- So sánh: 120 vs 150 → min = 120
- ...
- So sánh: 120 vs 90 → min = 90
- Tiếp tục so sánh tất cả...
Kết quả: Min = 90 (ở hàng 0, cột 9)
3. TÌM GIÁ TRỊ LỚN NHẤT (MAX)
Cách làm: Tương tự min nhưng tìm số lớn nhất
Quá trình:
- Bắt đầu: max = 120
- So sánh: 120 vs 180 → max = 180
- So sánh: 180 vs 200 → max = 200
- Tiếp tục...
Kết quả: Max = 200 (xuất hiện ở nhiều vị trí: hàng 0-cột 5, hàng 4-cột 5, hàng 11-cột 5)
4. TÍNH TỔNG TẤT CẢ
Cách tính: Cộng từng hàng, rồi cộng tổng các hàng
Tổng từng hàng:
- Hàng 0: 120+180+150+160+130+200+140+175+110+90 = 1,455
- Hàng 1: 130+170+160+155+135+190+145+180+115+100 = 1,480
- Hàng 2: 125+165+155+158+132+185+148+178+118+95 = 1,459
- Hàng 3: 135+175+160+162+140+195+150+182+120+105 = 1,524
- Hàng 4: 140+180+165+168+145+200+155+185+125+110 = 1,573
- Hàng 5: 138+178+162+166+143+198+152+184+122+108 = 1,551
- Hàng 6: 128+170+158+160+139+190+149+179+119+102 = 1,494
- Hàng 7: 132+172+161+163+142+192+151+181+121+104 = 1,519
- Hàng 8: 134+174+163+165+144+194+153+183+123+106 = 1,539
- Hàng 9: 136+176+164+167+146+196+154+186+124+107 = 1,556
- Hàng 10: 138+178+166+169+148+198+156+188+126+109 = 1,576
- Hàng 11: 140+180+168+170+150+200+158+190+128+111 = 1,595
Tổng cuối cùng: 1,455 + 1,480 + 1,459 + 1,524 + 1,573 + 1,551 + 1,494 + 1,519 + 1,539 + 1,556 + 1,576 + 1,595 = 18,321
5. TÍNH TRUNG BÌNH
Công thức: Trung bình = Tổng ÷ Số phần tử
Tính toán:
- Tổng = 18,321
- Số phần tử = 120
- Trung bình = 18,321 ÷ 120 = 152.675
6. TÍNH ĐỘ LỆCH CHUẨN
Bước 1: Tính sai lệch của mỗi số so với trung bình
Ví dụ với 5 số đầu tiên:
- 120 - 152.675 = -32.675
- 180 - 152.675 = 27.325
- 150 - 152.675 = -2.675
- 160 - 152.675 = 7.325
- 130 - 152.675 = -22.675
Bước 2: Bình phương các sai lệch
- (-32.675)² = 1,067.66
- (27.325)² = 746.66
- (-2.675)² = 7.16
- (7.325)² = 53.66
- (-22.675)² = 514.16
Bước 3: Làm tương tự cho tất cả 120 số và cộng lại
Bước 4: Chia cho số phần tử để có phương sai
Bước 5: Căn bậc 2 của phương sai = độ lệch chuẩn
7. TÍNH THỐNG KÊ THEO CỘT
Ví dụ cột 0 (số đầu tiên mỗi hàng):
- Các giá trị: 120, 130, 125, 135, 140, 138, 128, 132, 134, 136, 138, 140
- Tổng: 120+130+125+135+140+138+128+132+134+136+138+140 = 1,616
- Trung bình: 1,616 ÷ 12 = 134.67
- Min: 120
- Max: 140
Làm tương tự cho 9 cột còn lại...
8. TÌM TRUNG VỊ (MEDIAN)
Bước 1: Sắp xếp tất cả 120 số từ nhỏ đến lớn
Bước 2: Vì có 120 số (chẵn), trung vị = trung bình của số thứ 60 và 61
Cách sắp xếp thủ công:
- Tìm số nhỏ nhất: 90
- Tìm số nhỏ thứ 2: 95
- Tìm số nhỏ thứ 3: 100
- ...
- Tiếp tục đến số thứ 60 và 61
9. TÍNH PERCENTILE
Công thức: Vị trí = (Percentile ÷ 100) × (n - 1)
Ví dụ Percentile 25%:
- Vị trí = (25 ÷ 100) × (120 - 1) = 0.25 × 119 = 29.75
- Lấy giá trị ở vị trí 29 và 30 trong danh sách đã sắp xếp
- Nội suy: 0.75 × giá_trị_30 + 0.25 × giá_trị_29
10. ĐẾM THEO ĐIỀU KIỆN
Ví dụ: Đếm số phần tử > 150
Cách làm: Duyệt qua từng số và đếm
- 120 > 150? Không
- 180 > 150? Có → đếm = 1
- 150 > 150? Không
- 160 > 150? Có → đếm = 2
- ...
Tiếp tục cho tất cả 120 số
CÔNG CỤ HỖ TRỢ TÍNH TOÁN
Để tính nhanh hơn, bạn có thể:
- Sử dụng máy tính casio để cộng từng hàng
- Làm bảng Excel để kiểm tra kết quả
- Chia nhỏ công việc - tính từng phần rồi ghép lại
- Kiểm tra chéo - tính cùng 1 kết quả bằng 2 cách khác nhau
Lưu ý quan trọng:
- Tính toán thủ công rất dễ sai sót
- Nên kiểm tra lại nhiều lần
- Có thể dùng máy tính để hỗ trợ phép cộng/trừ/nhân/chia cơ bản
# Dữ liệu gốc dưới dạng list Python thuần
data = [
[120,180,150,160,130,200,140,175,110,90],
[130,170,160,155,135,190,145,180,115,100],
[125,165,155,158,132,185,148,178,118,95],
[135,175,160,162,140,195,150,182,120,105],
[140,180,165,168,145,200,155,185,125,110],
[138,178,162,166,143,198,152,184,122,108],
[128,170,158,160,139,190,149,179,119,102],
[132,172,161,163,142,192,151,181,121,104],
[134,174,163,165,144,194,153,183,123,106],
[136,176,164,167,146,196,154,186,124,107],
[138,178,166,169,148,198,156,188,126,109],
[140,180,168,170,150,200,158,190,128,111]
]
print("=" * 70)
print("TÍNH TOÁN THỦ CÔNG CÁC CÔNG THỨC NUMPY")
print("=" * 70)
# 1. THÔNG TIN CƠ BẢN
print("\n1. THÔNG TIN CƠ BẢN (thủ công):")
rows = len(data)
cols = len(data[0])
total_elements = rows * cols
print(f"Số hàng: {rows}")
print(f"Số cột: {cols}")
print(f"Tổng số phần tử: {total_elements}")
print(f"Kích thước: ({rows}, {cols})")
# 2. TẤT CẢ GIÁ TRỊ TRONG MẢNG (flatten thủ công)
print("\n2. CHUYỂN ĐỔI THÀNH DANH SÁCH 1 CHIỀU:")
all_values = []
for row in data:
for value in row:
all_values.append(value)
print(f"10 giá trị đầu tiên: {all_values[:10]}")
print(f"Tổng số phần tử sau flatten: {len(all_values)}")
# 3. GIÁ TRỊ MIN/MAX (thủ công)
print("\n3. TÌM MIN/MAX THỦ CÔNG:")
min_value = all_values[0] # Khởi tạo với giá trị đầu tiên
max_value = all_values[0]
min_position = (0, 0)
max_position = (0, 0)
for i in range(rows):
for j in range(cols):
current_value = data[i][j]
if current_value < min_value:
min_value = current_value
min_position = (i, j)
if current_value > max_value:
max_value = current_value
max_position = (i, j)
print(f"Giá trị nhỏ nhất: {min_value}")
print(f"Vị trí min: hàng {min_position[0]}, cột {min_position[1]}")
print(f"Giá trị lớn nhất: {max_value}")
print(f"Vị trí max: hàng {max_position[0]}, cột {max_position[1]}")
# 4. TỔNG VÀ TRUNG BÌNH (thủ công)
print("\n4. TỔNG VÀ TRUNG BÌNH THỦ CÔNG:")
total_sum = 0
for value in all_values:
total_sum += value
mean_value = total_sum / len(all_values)
print(f"Tổng tất cả: {total_sum}")
print(f"Trung bình: {mean_value:.2f}")
# 5. TRUNG VỊ (MEDIAN) thủ công
print("\n5. TRUNG VỊ (MEDIAN) THỦ CÔNG:")
# Sắp xếp thủ công bằng bubble sort
sorted_values = all_values.copy()
n = len(sorted_values)
for i in range(n):
for j in range(0, n - i - 1):
if sorted_values[j] > sorted_values[j + 1]:
sorted_values[j], sorted_values[j + 1] = sorted_values[j + 1], sorted_values[j]
print(f"5 giá trị nhỏ nhất: {sorted_values[:5]}")
print(f"5 giá trị lớn nhất: {sorted_values[-5:]}")
# Tính median
if n % 2 == 0:
median = (sorted_values[n//2 - 1] + sorted_values[n//2]) / 2
else:
median = sorted_values[n//2]
print(f"Trung vị: {median}")
# 6. ĐỘ LỆCH CHUẨN (STANDARD DEVIATION) thủ công
print("\n6. ĐỘ LỆCH CHUẨN THỦ CÔNG:")
# Bước 1: Tính tổng bình phương sai lệch
sum_squared_diff = 0
for value in all_values:
diff = value - mean_value
sum_squared_diff += diff * diff
# Bước 2: Tính phương sai (variance)
variance = sum_squared_diff / len(all_values)
# Bước 3: Tính độ lệch chuẩn (căn bậc 2 của phương sai)
std_dev = variance ** 0.5
print(f"Tổng bình phương sai lệch: {sum_squared_diff:.2f}")
print(f"Phương sai: {variance:.2f}")
print(f"Độ lệch chuẩn: {std_dev:.2f}")
# 7. THỐNG KÊ THEO HÀNG (thủ công)
print("\n7. THỐNG KÊ THEO HÀNG THỦ CÔNG:")
row_stats = []
for i, row in enumerate(data):
row_sum = 0
row_min = row[0]
row_max = row[0]
for value in row:
row_sum += value
if value < row_min:
row_min = value
if value > row_max:
row_max = value
row_mean = row_sum / len(row)
row_stats.append({
'row': i,
'sum': row_sum,
'mean': row_mean,
'min': row_min,
'max': row_max
})
print(f"Hàng {i}: Tổng={row_sum}, TB={row_mean:.1f}, Min={row_min}, Max={row_max}")
# 8. THỐNG KÊ THEO CỘT (thủ công)
print("\n8. THỐNG KÊ THEO CỘT THỦ CÔNG:")
col_stats = []
for j in range(cols):
col_sum = 0
col_values = []
# Lấy tất cả giá trị của cột j
for i in range(rows):
col_values.append(data[i][j])
col_sum += data[i][j]
col_mean = col_sum / len(col_values)
col_min = min(col_values)
col_max = max(col_values)
col_stats.append({
'col': j,
'sum': col_sum,
'mean': col_mean,
'min': col_min,
'max': col_max
})
print(f"Cột {j}: Tổng={col_sum}, TB={col_mean:.1f}, Min={col_min}, Max={col_max}")
# 9. PERCENTILES thủ công
print("\n9. PERCENTILES THỦ CÔNG:")
def calculate_percentile(sorted_list, percentile):
"""Tính percentile thủ công"""
n = len(sorted_list)
index = (percentile / 100) * (n - 1)
if index.is_integer():
return sorted_list[int(index)]
else:
lower_index = int(index)
upper_index = lower_index + 1
weight = index - lower_index
return sorted_list[lower_index] * (1 - weight) + sorted_list[upper_index] * weight
p25 = calculate_percentile(sorted_values, 25)
p50 = calculate_percentile(sorted_values, 50)
p75 = calculate_percentile(sorted_values, 75)
p90 = calculate_percentile(sorted_values, 90)
print(f"Percentile 25%: {p25:.2f}")
print(f"Percentile 50%: {p50:.2f}")
print(f"Percentile 75%: {p75:.2f}")
print(f"Percentile 90%: {p90:.2f}")
# 10. ĐẾM ĐIỀU KIỆN thủ công
print("\n10. ĐẾM THEO ĐIỀU KIỆN THỦ CÔNG:")
threshold = 150
count_above_threshold = 0
values_above_180 = []
for value in all_values:
if value > threshold:
count_above_threshold += 1
if value > 180:
values_above_180.append(value)
percentage_above = (count_above_threshold / len(all_values)) * 100
print(f"Số phần tử > {threshold}: {count_above_threshold}")
print(f"Tỷ lệ % phần tử > {threshold}: {percentage_above:.1f}%")
print(f"Các giá trị > 180: {values_above_180}")
# 11. GIÁ TRỊ DUY NHẤT (UNIQUE) thủ công
print("\n11. GIÁ TRỊ DUY NHẤT THỦ CÔNG:")
unique_values = []
for value in all_values:
if value not in unique_values:
unique_values.append(value)
# Sắp xếp unique values
for i in range(len(unique_values)):
for j in range(0, len(unique_values) - i - 1):
if unique_values[j] > unique_values[j + 1]:
unique_values[j], unique_values[j + 1] = unique_values[j + 1], unique_values[j]
print(f"Số giá trị duy nhất: {len(unique_values)}")
print(f"10 giá trị duy nhất đầu tiên: {unique_values[:10]}")
# 12. CHUẨN HÓA DỮ LIỆU (STANDARDIZATION) thủ công
print("\n12. CHUẨN HÓA DỮ LIỆU THỦ CÔNG:")
print("Công thức: (giá_trị - trung_bình) / độ_lệch_chuẩn")
normalized_sample = []
for i in range(min(5, len(all_values))): # Chỉ hiển thị 5 giá trị đầu
original = all_values[i]
normalized = (original - mean_value) / std_dev
normalized_sample.append(normalized)
print(f"Giá trị {original} -> Chuẩn hóa: {normalized:.3f}")
print(f"5 giá trị chuẩn hóa đầu tiên: {[round(x, 3) for x in normalized_sample]}")
print("\n" + "=" * 70)
print("HOÀN THÀNH TÍNH TOÁN THỦ CÔNG!")
print("=" * 70)
print("\nCÁC CÔNG THỨC ĐÃ TÍNH:")
print("- Min/Max và vị trí")
print("- Tổng, trung bình")
print("- Trung vị (median)")
print("- Độ lệch chuẩn và phương sai")
print("- Thống kê theo hàng/cột")
print("- Percentiles")
print("- Đếm theo điều kiện")
print("- Giá trị duy nhất")
print("- Chuẩn hóa dữ liệu")